Walid Krichene
I am a Principal Engineer at Microsoft CoreAI, where I work on algorithms for LLM efficiency.
Previously, I was at Google Research, where I worked on optimization algorithms, differential privacy, and recommender systems, and where I taught with ML@CapitalG.
I did my Ph.D. in Electrical Engineering and Computer Sciences at UC Berkeley, where I was advised by Alex Bayen and Peter Bartlett, on Continuous and discrete algorithms for optimization.
News
- MAC Attention, a Match-Amend-Complete Scheme for Fast and Accurate Attention Computation is accepted to MLSYS 2026!
- We have fine-tuned and released a decensored, safer, quantized version of the DS-R1 model!
- Private Learning with Public Features is accepted to AISTATS 2024!
- Two papers accepted to ICML 2023! On reciprocity in machine learning (oral), and DP with long tails.
- On Sampled Metrics for Item Recommendation won the Best Paper Award at KDD2020!
pdf Talk
- Fractally expanded Movielens 1B is now hosted on the Movielens website.
- The Recommendation Systems class is now open-sourced as part of Google's ML courses.
- I will teach at the Nassma Machine Learning summer school from Jun 24-29, 2019.
Introduction to Optimization
Introduction to Recommender Systems. Colab
- I will present our paper on efficient training via Gramian estimation at ICLR May 6-9, 2019.
- I will give a talk on continuous-time optimization at the UCSC Applied Mathematics seminar on Jan 28 2019.
- I will give a talk on continuous-time dynamics for stochastic optimization at the Bay Area Optimization meeting (BayOpt 2018) on May 18 2018.
- I will give a talk on continuous-time optimization methods at the Machine Learning and Trends in Optimization seminar at UW, on Feb 20, 2018. slides
- Our paper on Acceleration and Averaging in Stochastic Descent Dynamics is selected for a spotlight presentation at NeurIPS. arxiv spotlight video
- I will attend the Heidelberg Laureate Forum. Sep. 24, 2017.
- I will give my dissertation talk on Continuous and Discrete Dynamics for Online Learning and Convex Optimization on August 18, 2016 at 3pm, in Cory 337.
- I will be giving a talk at the IPAM on distributed learning, estimation and control for routing (November 2015).
- Our paper on accelerated mirror descent in continuous and discrete time is selected for a spotlight presentation at NeurIPS. Dec. 2015.
Publications
-
J. Yao, S. Jacobs, W. Krichene, M. Tanaka, D. Panda. MAC Attention: a Match-Amend-Complete Scheme for Fast and Accurate Attention Computation, MLSys 2026.
bibtex abstract
@INPROCEEDINGS{yao2026mac, author = {Yao, Jinghan and Jacobs, Sam and Krichene, Walid and Tanaka, Masahiro and Panda, Dhabaleswar}, title = {{MAC} Attention: a Match-Amend-Complete Scheme for Fast and Accurate Attention Computation}, booktitle = {Proceedings of Machine Learning and Systems}, volume={9}, year = {2026}, } -
W. Krichene, N. Mayoraz, S. Rendle, S. Song, A. Thakurta, and L. Zhang. Private Learning with Public Features, AISTATS 2024.
bibtex abstract
@INPROCEEDINGS{krichene2024private, author = {Krichene, Walid and Mayoraz, Nicolas and Rendle, Steffen and Song, Shuang and Thakurta, Abhradeep and Zhang, Li}, title = {Private Learning with Public Features}, booktitle = {Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS)}, year = {2024}, }We study a class of private learning problems in which the data is a join of private and public features. This is often the case in private personalization tasks such as recommendation or ad prediction, in which features related to individuals are sensitive, while features related to items (the movies or songs to be recommended, or the ads to be shown to users) are publicly available and do not require protection. A natural question is whether private algorithms can achieve higher utility in the presence of public features. We give a positive answer for multi-encoder models where one of the encoders operates on public features. We develop new algorithms that take advantage of this separation by only protecting certain sufficient statistics (instead of adding noise to the gradient). This method has a guaranteed utility improvement for linear regression, and importantly, achieves the state of the art on two standard private recommendation benchmarks, demonstrating the importance of methods that adapt to the private-public feature separation.
-
M. Sundararajan and W. Krichene. Inflow, Outflow, and Reciprocity in Machine Learning, ICML 2023 (oral).
bibtex abstract pdf Oral
@InProceedings{sundararajan23inflow, title = {Inflow, Outflow, and Reciprocity in Machine Learning}, author = {Sundararajan, Mukund and Krichene, Walid}, booktitle = {Proceedings of the 40th International Conference on Machine Learning}, pages = {33195--33208}, year = {2023}, volume = {202}, series = {Proceedings of Machine Learning Research}, }Data is pooled across entities (individuals or enterprises) to create machine learning models, and sometimes, the entities that contribute the data also benefit from the models. Consider for instance a recommender system (e.g. Spotify, Instagram or YouTube), a health care app that predicts the risk for some disease, or a service built by pooling data across enterprises. In this work we propose a framework to study this value exchange, i.e., we model and measure contributions (outflows), benefits (inflows) and the balance between contributions and benefits (the degree of reciprocity). We show theoretically, and via experiments that under certain distributional assumptions, some classes of models are approximately reciprocal. These results only scratch the surface; we conclude with several open directions.
-
W. Krichene, P. Jain, S. Song, M, Sundararajan, A. Thakurta, and L. Zhang. Multi-task Differential Privacy under Distribution Skew, ICML 2023.
bibtex abstract pdf Talk
@InProceedings{krichene23multi, title = {Multi-Task Differential Privacy Under Distribution Skew}, author = {Krichene, Walid and Jain, Prateek and Song, Shuang and Sundararajan, Mukund and Guha Thakurta, Abhradeep and Zhang, Li}, booktitle = {Proceedings of the 40th International Conference on Machine Learning}, pages = {17784--17807}, year = {2023}, volume = {202}, series = {Proceedings of Machine Learning Research}, publisher = {PMLR}, }We study the problem of multi-task learning under user-level differential privacy, in which n users contribute data to m tasks, each involving a subset of users. One important aspect of the problem, that can significantly impact quality, is the distribution skew among tasks. Tasks that have much fewer data samples than others are more susceptible to the noise added for privacy. It is natural to ask whether algorithms can adapt to this skew to improve the overall utility. We give a systematic analysis of the problem, by studying how to optimally allocate a user’s privacy budget among tasks. We propose a generic algorithm, based on an adaptive reweighting of the empirical loss, and show that in the presence of distribution skew, this gives a quantifiable improvement of excess empirical risk. Experimental studies on recommendation problems that exhibit a long tail of small tasks, demonstrate that our methods significantly improve utility, achieving the state of the art on two standard benchmarks.
-
M. Curmei, W. Krichene, L. Zhang, and M. Sundararajan. Private Matrix Factorization with Public Item Features, RecSys 2023.
bibtex abstract pdf
@inproceedings{10.1145/3604915.3608833, author = {Curmei, Mihaela and Krichene, Walid and Zhang, Li and Sundararajan, Mukund}, title = {Private Matrix Factorization with Public Item Features}, year = {2023}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, booktitle = {Proceedings of the 17th ACM Conference on Recommender Systems}, pages = {805–812}, numpages = {8}, location = {Singapore, Singapore}, series = {RecSys '23} }We consider the problem of training private recommendation models with access to public item features. Training with Differential Privacy (DP) offers strong privacy guarantees, at the expense of loss in recommendation quality. We show that incorporating public item features during training can help mitigate this loss in quality. We propose a general approach based on collective matrix factorization (CMF), that works by simultaneously factorizing two matrices: the user feedback matrix (representing sensitive data) and an item feature matrix that encodes publicly available (non-sensitive) item information. The method is conceptually simple, easy to tune, and highly scalable. It can be applied to different types of public item data, including: (1) categorical item features; (2) item-item similarities learned from public sources; and (3) publicly available user feedback. Furthermore, these data modalities can be collectively utilized to fully leverage public data. Evaluating our method on a standard DP recommendation benchmark, we find that using public item features significantly narrows the quality gap between private models and their non-private counterparts. As privacy constraints become more stringent, models rely more heavily on public side features for recommendation. This results in a smooth transition from collaborative filtering to item-based contextual recommendations.
-
H. Mehta, W. Krichene, A. Thakurta, A. Kurakin, and A. Cutkosky
Differentially private image classification from features, TMLR 2022.
bibtex abstract pdf Blog
@article{ mehta2023differentially, title={Differentially Private Image Classification from Features}, author={Harsh Mehta and Walid Krichene and Abhradeep Guha Thakurta and Alexey Kurakin and Ashok Cutkosky}, journal={Transactions on Machine Learning Research}, issn={2835-8856}, year={2023}, url={https://openreview.net/forum?id=Cj6pLclmwT}, note={Expert Certification} }In deep learning, leveraging transfer learning has recently been shown to be an effective strategy for training large high performance models with Differential Privacy (DP). Moreover, somewhat surprisingly, recent works have found that privately training just the last layer of a pre-trained model provides the best utility with DP. While past studies largely rely on using first-order differentially private training algorithms like DP-SGD for training large models, in the specific case of privately learning from features, we observe that computational burden is often low enough to allow for more sophisticated optimization schemes, including second-order methods. To that end, we systematically explore the effect of design parameters such as loss function and optimization algorithm. We find that, while commonly used logistic regression performs better than linear regression in the non-private setting, the situation is reversed in the private setting. We find that least-squares linear regression is much more effective than logistic regression from both privacy and computational standpoint, especially at stricter epsilon values (ε < 1). On the optimization side, we also explore using Newton’s method, and find that second-order information is quite helpful even with privacy, although the benefit significantly diminishes with stricter privacy guarantees. While both methods use second-order information, least squares is more effective at lower epsilon values while Newton’s method is more effective at larger epsilon values. To combine the benefits of both methods, we propose a novel optimization algorithm called DP-FC, which leverages feature covariance instead of the Hessian of the logistic regression loss and performs well across all ε values we tried. With this, we obtain new SOTA results on ImageNet-1k, CIFAR-100 and CIFAR-10 across all values of ε typically considered. Most remarkably, on ImageNet-1K, we obtain top-1 accuracy of 88% under DP guarantee of (8, 8e−7) and 84.3% under (0.1, 8e−7).
- S. Rendle, W. Krichene, L. Zhang, and Y. Koren. Revisiting the performance of ials on item recommendation benchmarks, RecSys 2022.
bibtex abstract pdf
@inproceedings{rendle2022revisiting, author = {Rendle, Steffen and Krichene, Walid and Zhang, Li and Koren, Yehuda}, title = {Revisiting the Performance of iALS on Item Recommendation Benchmarks}, year = {2022}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, booktitle = {Proceedings of the 16th ACM Conference on Recommender Systems}, pages = {427–435}, numpages = {9}, location = {Seattle, WA, USA}, series = {RecSys '22} }Matrix factorization learned by implicit alternating least squares (iALS) is a popular baseline in recommender system research publications. iALS is known to be one of the most computationally efficient and scalable collaborative filtering methods. However, recent studies suggest that its prediction quality is not competitive with the current state of the art, in particular autoencoders and other item-based collaborative filtering methods. In this work, we revisit four well-studied benchmarks where iALS was reported to perform poorly and show that with proper tuning, iALS is highly competitive and outperforms any method on at least half of the comparisons. We hope that these high quality results together with iALS’s known scalability spark new interest in applying and further improving this decade old technique.
-
S. Chien, P. Jain, W. Krichene*, S. Rendle, S. Song, A. Thakurta* and L. Zhang. Private Alternating Least Squares: Practical Private Matrix Completion with Tighter Rates, ICML 2021 (long oral).
bibtex abstract pdf Talk
@INPROCEEDINGS{chien2021dpals, author = {Chien, Steve and Jain, Prateek and Krichene, Walid and Rendle, Steffen and Song, Shuang and Thakurta, Abhradeep and Zhang, Li}, title = {Private Alternating Least Squares: Practical Private Matrix Completion with Tighter Rates}, booktitle = {Proceedings of the 38th International Conference on Machine Learning}, pages = {1877--1887}, year = {2021}, }We study the problem of differentially private (DP) matrix completion under user-level privacy. We design a joint differentially private variant of the popular Alternating-Least-Squares (ALS) method that achieves: i) (nearly) optimal sample complexity for matrix completion (in terms of number of items, users), and ii) the best known privacy/utility trade-off both theoretically, as well as on benchmark data sets. In particular, we provide the first global convergence analysis of ALS with noise introduced to ensure DP, and show that, in comparison to the best known alternative (the Private Frank-Wolfe algorithm by Jain et al. (2018)), our error bounds scale significantly better with respect to the number of items and users, which is critical in practical problems. Extensive validation on standard benchmarks demonstrate that the algorithm, in combination with carefully designed sampling procedures, is significantly more accurate than existing techniques, thus promising to be the first practical DP embedding model.
-
W. Kong*, W. Krichene*, N. Mayoraz, S. Rendle and L. Zhang. Rankmax: An Adaptive Projection Alternative to the Softmax Function, NeurIPS 2020.
bibtex abstract pdf Talk
@INPROCEEDINGS{kong2020rankmax, author = {Kong, William and Krichene, Walid and Mayoraz, Nicolas and Rendle, Steffen and Zhang, Li}, title = {Rankmax: An Adaptive Projection Alternative to the Softmax Function}, booktitle = {Thirty-fourth Conference on Neural Information Processing Systems}, Year = {2020} }Many machine learning models involve mapping a score vector to a probability vector. Usually, this is done by projecting the score vector onto a probability simplex, and such projections are often characterized as Lipschitz continuous approximations of the argmax function, whose Lipschitz constant is controlled by a parameter that is similar to a softmax temperature. The aforementioned parameter has been observed to affect the quality of these models and is typically either treated as a constant or decayed over time. In this work, we propose a method that adapts this parameter to individual training examples. The resulting method exhibits desirable properties, such as sparsity of its support and numerically efficient implementation, and we find that it significantly outperforms competing non-adaptive projection methods. In our analysis, we also derive the general solution of (Bregman) projections onto the (n, k)–simplex, a result which may be of independent interest.
-
W. Krichene, K. F. Caluya and A. Halder. Global Convergence of Second-order Dynamics in Two-layer Neural Networks, technical report, 2020.
bibtex abstract pdf
@INPROCEEDINGS{krichene2020global, author = {Krichene, Walid and Caluya, Kenneth F. and Halder, Abhishek}, title = {Global Convergence of Second-order Dynamics in Two-layer Neural Networks}, Volume = {abs/2007.06852}, Journal = {CoRR}, Year = {2020} }Recent results have shown that for two-layer fully connected neural networks, gradient flow converges to a global optimum in the infinite width limit, by making a connection between the mean field dynamics and the Wasserstein gradient flow. These results were derived for first-order gradient flow, and a natural question is whether second-order dynamics, i.e., dynamics with momentum, exhibit a similar guarantee. We show that the answer is positive for the heavy ball method. In this case, the resulting integro-PDE is a nonlinear kinetic Fokker Planck equation, and unlike the first-order case, it has no apparent connection with the Wasserstein gradient flow. Instead, we study the variations of a Lyapunov functional along the solution trajectories to characterize the stationary points and to prove convergence. While our results are asymptotic in the mean field limit, numerical simulations indicate that global convergence may already occur for reasonably small networks.
-
W. Krichene and S. Rendle. On Sampled Metrics for Item Recommendation, KDD 2020. Best Paper Award
bibtex abstract pdf Talk
@INPROCEEDINGS{krichene2020sampled, author = {Krichene, Walid and Rendle, Steffen}, title = {On Sampled Metrics for Item Recommendation}, booktitle = {26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '20)}, Year = {2020} }The task of item recommendation requires ranking a large catalogue of items given a context. Item recommendation algorithms are evaluated using ranking metrics that depend on the positions of relevant items. To speed up the computation of metrics, recent work often uses sampled metrics where only a smaller set of random items and the relevant items are ranked. This paper investigates sampled metrics in more detail and shows that they are inconsistent with their exact version, in the sense that they do not persist relative statements, e.g., recommender A is better than B, not even in expectation. Moreover, the smaller the sampling size, the less difference there is between metrics, and for very small sampling size, all metrics collapse to the AUC metric. We show that it is possible to improve the quality of the sampled metrics by applying a correction, obtained by minimizing different criteria such as bias or mean squared error. We conclude with an empirical evaluation of the naive sampled metrics and their corrected variants. To summarize, our work suggests that sampling should be avoided for metric calculation, however if an experimental study needs to sample, the proposed corrections can improve the quality of the estimate.
-
S. Rendle, W. Krichene, L. Zhang and J. Anderson. Neural Collaborative Filtering vs. Matrix Factorization Revisited, RecSys 2020.
bibtex abstract pdf Talk slides
@inproceedings{rendle2020ncf, author = {Rendle, Steffen and and Krichene, Walid and Zhang, Li and Anderson, John}, title = {Neural Collaborative Filtering vs. Matrix Factorization Revisited}, booktitle={14th ACM Conference on Recommender Systems (RecSys)}, year = {2020} }Embedding based models have been the state of the art in collaborative filtering for over a decade. Traditionally, the dot product or higher order equivalents have been used to combine two or more embeddings, e.g., most notably in matrix factorization. In recent years, it was suggested to replace the dot product with a learned similarity e.g. using a multilayer perceptron (MLP). This approach is often referred to as neural collaborative filtering (NCF). In this work, we revisit the experiments of the NCF paper that popularized learned similarities using MLPs. First, we show that with a proper hyperparameter selection, a simple dot product substantially outperforms the proposed learned similarities. Second, while a MLP can in theory approximate any function, we show that it is non-trivial to learn a dot product with an MLP. Finally, we discuss practical issues that arise when applying MLP based similarities and show that MLPs are too costly to use for item recommendation in production environments while dot products allow to apply very efficient retrieval algorithms. We conclude that MLPs should be used with care as embedding combiner and that dot products might be a better default choice.
-
J. Anderson, Q. Huang, W. Krichene, S. Rendle and L. Zhang. Superbloom: Bloom filter meets Transformer, 2020.
bibtex abstract pdf
@article{anderson2020superbloom, author = {Anderson, John and Huang, Qingqing and Krichene, Walid and Rendle, Steffen and Zhang, Li}, title = {Superbloom: Bloom filter meets Transformer}, Volume = {abs/2002.04723}, Journal = {CoRR}, Year = {2020} }We extend the idea of word pieces in natural language models to machine learning tasks on opaque ids. This is achieved by applying hash functions to map each id to multiple hash tokens in a much smaller space, similarly to a Bloom filter. We show that by applying a multi-layer Transformer to these Bloom filter digests, we are able to obtain models with high accuracy. They outperform models of a similar size without hashing and, to a large degree, models of a much larger size trained using sampled softmax with the same computational budget. Our key observation is that it is important to use a multi-layer Transformer for Bloom filter digests to remove ambiguity in the hashed input. We believe this provides an alternative method to solving problems with large vocabulary size.
-
F. Belletti, K. Lakshmanan, W. Krichene, N. Mayoraz, Y. Chen, J. Anderson, T. Robie, T. Oguntebi, D. Shirron and A. Bleiwess. Scaling Up Collaborative Filtering Data Sets through Randomized Fractal Expansions, 2019.
bibtex abstract pdf
@article{belletti2019scaling, author = {Belletti, Francois and Lakshmanan, Karthik and Krichene, Walid and Mayoraz, Nicolas and Chen, Yi-Fan and Anderson, John and Robie, Taylor and Oguntebi, Tayo and Shirron, Dan and Bleiwess, Amit}, title = {Scaling Up Collaborative Filtering Data Sets through Randomized Fractal Expansions}, Volume = {abs/1905.09874}, Journal = {CoRR}, Year = {2019} }Recommender system research suffers from a disconnect between the size of academic data sets and the scale of industrial production systems. In order to bridge that gap, we propose to generate large-scale user/item interaction data sets by expanding pre-existing public data sets. Our key contribution is a technique that expands user/item incidence matrices matrices to large numbers of rows (users), columns (items), and non-zero values (interactions). The proposed method adapts Kronecker Graph Theory to preserve key higher order statistical properties such as the fat-tailed distribution of user engagements, item popularity, and singular value spectra of user/item interaction matrices. Preserving such properties is key to building large realistic synthetic data sets which in turn can be employed reliably to benchmark recommender systems and the systems employed to train them. We further apply our stochastic expansion algorithm to the binarized MovieLens 20M data set, which comprises 20M interactions between 27K movies and 138K users. The resulting expanded data set has 1.2 B ratings, 2.2 M users, and 855K items, which can be scaled up or down.
-
W. Krichene, N. Mayoraz, S. Rendle, L. Zhang, X. Yi, L. Hong, E. Chi and J. Anderson. Efficient Training on Very Large Corpora via Gramian Estimation, ICLR 2019.
bibtex abstract pdf poster
@incollection{krichene2019efficient, author = {Krichene, Walid and Mayoraz, Nicolas and Rendle, Steffen and Zhang, Li and Yi, Xinyang and Hong, Lichan and Chi, Ed and Anderson, John}, title = {Efficient Training on Very Large Corpora via Gramian Estimation}, booktitle = {7th International Conference on Learning Representations}, Year = {2019} }We study the problem of learning similarity functions over very large corpora using neural network embedding models. These models are typically trained using SGD with random sampling of unobserved pairs, with a sample size that grows quadratically with the corpus size, making it expensive to scale. We propose new efficient methods to train these models without having to sample unobserved pairs. Inspired by matrix factorization, our approach relies on adding a global quadratic penalty and expressing this term as the inner-product of two generalized Gramians. We show that the gradient of this term can be efficiently computed by maintaining estimates of the Gramians, and develop variance reduction schemes to improve the quality of the estimates. We conduct large-scale experiments that show a significant improvement both in training time and generalization performance compared to sampling methods.
-
W. Krichene, M. C. Bourguiba, K. Lam, and A. Bayen. On Learning How Players Learn: Estimation of Learning Dynamics in the Routing Game.
ACM Transactions on Cyber-Physical Systems, 2018.
bibtex abstract pdf
@article{krichene2018tcps, author = {Krichene, Walid and Bourguiba, Mohamed Chedhli and Tlam, Kiet and Bayen, Alexandre}, title = {On Learning How Players Learn: Estimation of Learning Dynamics in the Routing Game}, journal = {ACM Trans. Cyber-Phys. Syst.}, issue_date = {February 2018}, volume = {2}, number = {1}, month = jan, year = {2018}, issn = {2378-962X}, pages = {6:1--6:23}, articleno = {6}, numpages = {23}, doi = {10.1145/3078620}, acmid = {3078620}, publisher = {ACM}, address = {New York, NY, USA}, keywords = {Routing game, behavioral experiment, sequential decision model}, }The routing game models congestion in transportation networks, communication networks, and other cyber-physical systems in which agents compete for shared resources. We consider an online learning model of player dynamics: at each iteration, every player chooses a route (or a probability distribution over routes, which corresponds to a flow allocation over the physical network), then the joint decision of all players determines the costs of each path, which are then revealed to the players.
We pose the following estimation problem: given a sequence of player decisions and the corresponding costs, we would like to estimate the parameters of the learning model. We consider, in particular, entropic mirror descent dynamics and reduce the problem to estimating the learning rates of each player.
In order to demonstrate our methods, we developed a web application that allows players to participate in a distributed, online routing game, and we deployed the application on Amazon Mechanical Turk. When players log in, they are assigned an origin and destination on a shared network. They can choose, at each iteration, a distribution over their available routes, and each player seeks to minimize her own cost. We collect a dataset using this platform, then apply the proposed method to estimate the learning rates of each player. We observe, in particular, that after an exploration phase, the joint decision of the players remains within a small distance of the set of equilibria. We also use the estimated model parameters to predict the flow distribution over routes, and compare our predictions to the actual distributions, showing that the online learning model can be used as a predictive model over short horizons. Finally, we discuss some of the qualitative insights from the experiments, and give directions for future research.
-
S. Samaranayake, W. Krichene, J. Reilly, M. Delle Monache, P. Goatin, and A. Bayen. Discrete-Time System Optimal Dynamic Traffic Assignment (SO-DTA) with Partial Control for Physical Queuing Networks. Transportation Science, 2018.
bibtex abstract
@article{samaranayake2018, author = {Samaranayake, Samitha and Krichene, Walid and Reilly, Jack and Monache, Maria Laura Delle and Goatin, Paola and Bayen, Alexandre}, title = {Discrete-Time System Optimal Dynamic Traffic Assignment (SO-DTA) with Partial Control for Physical Queuing Networks}, journal = {Transportation Science}, year = {2018}, doi = {10.1287/trsc.2017.0800}, }We consider the System Optimal Dynamic Traffic Assignment (SO-DTA) problem with Partial Control for general networks with physical queuing. Our goal is to optimally control any subset of the networks agents to minimize the total congestion of all agents in the network. We adopt a flow dynamics model that is a Godunov discretization of the Lighthill–Williams–Richards partial differential equation with a triangular flux function and a corresponding multicommodity junction solver. The partial control formulation generalizes the SO-DTA problem to consider cases where only a fraction of the total flow can be controlled, as may arise in the context of certain incentive schemes. This leads to a nonconvex multicommodity optimization problem. We define a multicommodity junction model that only requires full Lagrangian paths for the controllable agents, and aggregate turn ratios for the noncontrollable (selfish) agents. We show how the resulting finite horizon nonlinear optimal control problem can be efficiently solved using the discrete adjoint method, leading to gradient computations that are linear in the size of the state space and the controls.
-
W. Krichene and P. Bartlett. Acceleration and Averaging in Stochastic Descent Dynamics.
NeurIPS 2017 (spotlight).
bibtex abstract pdf supplement arxiv spotlight
@incollection{NIPS2017_7256, title = {Acceleration and Averaging in Stochastic Descent Dynamics}, author = {Krichene, Walid and Bartlett, Peter L}, booktitle = {Advances in Neural Information Processing Systems 30}, editor = {I. Guyon and U. V. Luxburg and S. Bengio and H. Wallach and R. Fergus and S. Vishwanathan and R. Garnett}, pages = {6796--6806}, year = {2017}, publisher = {Curran Associates, Inc.}, }We formulate and study a general family of (continuous-time) stochastic dynamics for accelerated first-order minimization of smooth convex functions. Building on an averaging formulation of accelerated mirror descent, we propose a stochastic variant in which the gradient is contaminated by noise, and study the resulting stochastic differential equation. We prove a bound on the rate of change of an energy function associated with the problem, then use it to derive estimates of convergence rates of the function values (almost surely and in expectation), both for persistent and asymptotically vanishing noise. We discuss the interaction between the parameters of the dynamics (learning rate and averaging rates) and the covariation of the noise process. In particular, we show how the asymptotic rate of covariation affects the choice of parameters and, ultimately, the convergence rate.
-
W. Krichene, J. D. Reilly, S. Amin, and A. Bayen. Stackelberg Routing on Parallel Transportation Networks. Book Chapter, in Handbook of Dynamic Game Theory, 2017.
bibtex abstract pdf
@Inbook{krichene2017stackelberg, author="Krichene, Walid and Reilly, Jack D. and Amin, Saurabh and Bayen, Alexandre M.", editor="Basar, Tamer and Zaccour, Georges", title="Stackelberg Routing on Parallel Transportation Networks", bookTitle="Handbook of Dynamic Game Theory", year="2017", publisher="Springer International Publishing", pages="1--35", isbn="978-3-319-27335-8", doi="10.1007/978-3-319-27335-8_26-1", }This chapter presents a game theoretic framework for studying Stackelberg routing games on parallel transportation networks. A new class of latency functions is introduced to model congestion due to the formation of physical queues, inspired from the fundamental diagram of traffic. For this new class, some results from the classical congestion games literature (in which latency is assumed to be a nondecreasing function of the flow) do not hold. A characterization of Nash equilibria is given, and it is shown, in particular, that there may exist multiple equilibria that have different total costs. A simple polynomial-time algorithm is provided, for computing the best Nash equilibrium, i.e., the one which achieves minimal total cost. In the Stackelberg routing game, a central authority (leader) is assumed to have control over a fraction of the flow on the network (compliant flow), and the remaining flow responds selfishly. The leader seeks to route the compliant flow in order to minimize the total cost. A simple Stackelberg strategy, the non-compliant first (NCF) strategy, is introduced, which can be computed in polynomial time, and it is shown to be optimal for this new class of latency on parallel networks. This work is applied to modeling and simulating congestion mitigation on transportation networks, in which a coordinator (traffic management agency) can choose to route a fraction of compliant drivers, while the rest of the drivers choose their routes selfishly.
-
W. Krichene. Continuous and Discrete Time Dynamics for Online Learning and Convex Optimization (Ph.D. thesis, UC Berkeley, 2016).
bibtex abstract pdf
@phdthesis{Krichene:EECS-2016-156, Author = {Krichene, Walid}, Title = {Continuous and Discrete Dynamics for Online Learning and Convex Optimization}, School = {EECS Department, University of California, Berkeley}, Year = {2016}, Month = {Sep}, Number = {UCB/EECS-2016-156}, }Online learning and convex optimization algorithms have become essential tools for solving problems in modern machine learning, statistics and engineering. Many algorithms for online learning and convex optimization can be interpreted as a discretization of a continuous time process, and studying the continuous time dynamics offers many advantages: the analysis is often simpler and more elegant in continuous time, it provides insights and leads to new interpretations of the discrete process, and streamlines the design of new algorithms, obtained by deriving the dynamics in continuous time, then discretizing. In this thesis, we apply this paradigm to two problems: the study of decision dynamics for online learning in games, and the design and analysis of accelerated methods for convex optimization.
In the first part of the thesis, we study online learning dynamics for a class of games called non-atomic convex potential games, which are used for example to model congestion in transportation and communication networks. We make a connection between the discrete Hedge algorithm for online learning, and an ODE on the simplex, known as the replicator dynamics. We study the asymptotic properties of the ODE, then by discretizing the ODE and using results from stochastic approximation theory, we derive a new class of online learning algorithms with asymptotic convergence guarantees. We further give a more refined analysis of these dynamics and their convergence rates. Then, using the Hedge algorithm as a model of decision dynamics, we pose and study two related problems: the problem of estimating the learning rates of the Hedge algorithm given observations on its sequence of decisions, and the problem of optimal control under Hedge dynamics.
In the second part, we study first-order accelerated dynamics for constrained convex optimization. We develop a method to design an ODE for the problem using an inverse Lyapunov argument: we start from an energy function that encodes the constraints of the problem and the desired convergence rate, then design an ODE tailored to that energy function. Then, by carefully discretizing the ODE, we obtain a family of accelerated algorithms with optimal rate of convergence. This results in a unified framework to derive and analyze most known first-order methods, from gradient descent and mirror descent to their accelerated versions. We give different interpretations of the ODE, inspired from physics and statistics. In particular, we give an averaging interpretation of accelerated dynamics, and derive simple sufficient conditions on the averaging scheme to guarantee a given rate of convergence. We also develop an adaptive averaging heuristic that empirically speeds up the convergence, and in many cases performs significantly better than popular heuristics such as restarting.
-
W. Krichene, A. Bayen and P. Bartlett. Adaptive Averaging in Accelerated Descent Dynamics. NeurIPS 2016 (spotlight).
bibtex abstract pdf supplement spotlight
@incollection{NIPS2016_6553, title = {Adaptive Averaging in Accelerated Descent Dynamics}, author = {Krichene, Walid and Bayen, Alexandre and Bartlett, Peter L}, booktitle = {Advances in Neural Information Processing Systems 29}, editor = {D. D. Lee and M. Sugiyama and U. V. Luxburg and I. Guyon and R. Garnett}, pages = {2991--2999}, year = {2016}, publisher = {Curran Associates, Inc.} }We study accelerated descent dynamics for constrained convex optimization. This dynamics can be described naturally as a coupling of a dual variable accumulating gradients at a given rate η(t), and a primal variable obtained as the weighted average of the mirrored dual trajectory, with weights w(t). Using a Lyapunov argument, we give sufficient conditions on η and w to achieve a desired convergence rate. As an example, we show that the replicator dynamics (an example of mirror descent on the simplex) can be accelerated using a simple averaging scheme. We then propose an adaptive averaging heuristic which adaptively computes the weights to speed up the decrease of the Lyapunov function. We provide guarantees on adaptive averaging in continuous-time, prove that it preserves the quadratic convergence rate of accelerated first-order methods in discrete-time, and give numerical experiments to compare it with existing heuristics, such as adaptive restarting. The experiments indicate that adaptive averaging performs at least as well as adaptive restarting, with significant improvements in some cases.
-
M. Balandat, W. Krichene, A. Bayen and C. Tomlin. Minimizing regret on reflexive Banach spaces and Nash equilibria in continuous zero-sum games.
NeurIPS 2016.
bibtex abstract pdf supplement
@incollection{NIPS2016_6216, title = {Minimizing Regret on Reflexive Banach Spaces and Nash Equilibria in Continuous Zero-Sum Games}, author = {Balandat, Maximilian and Krichene, Walid and Tomlin, Claire and Bayen, Alexandre}, booktitle = {Advances in Neural Information Processing Systems 29}, editor = {D. D. Lee and M. Sugiyama and U. V. Luxburg and I. Guyon and R. Garnett}, pages = {154--162}, year = {2016}, publisher = {Curran Associates, Inc.}, }We study a general adversarial online learning problem, in which we are given a decision set X' in a reflexive Banach space X and a sequence of reward vectors in the dual space of X. At each iteration, we choose an action from X', based on the observed sequence of previous rewards. Our goal is to minimize regret, defined as the gap between the realized reward and the reward of the best fixed action in hindsight. Using results from infinite dimensional convex analysis, we generalize the method of Dual Averaging (or Follow the Regularized Leader) to our setting and obtain upper bounds on the worst-case regret that generalize many previous results. Under the assumption of uniformly continuous rewards, we obtain explicit regret bounds in a setting where the decision set is the set of probability distributions on a compact metric space S. Importantly, we make no convexity assumptions on either the set S or the reward functions. We also prove a general lower bound on the worst-case regret for any online algorithm. We then apply these results to the problem of learning in repeated two-player zero-sum games on compact metric spaces. In doing so, we first prove that if both players play a Hannan-consistent strategy, then with probability 1 the empirical distributions of play weakly converge to the set of Nash equilibria of the game. We then show that, under mild assumptions, Dual Averaging on the (infinite-dimensional) space of probability distributions indeed achieves Hannan-consistency.
-
W. Krichene, M. Suarez Castillo, and A. Bayen. On Social Optimal Routing Under Selfish Learning. Transactions on Contol of Network Systems (TCNS), 2016.
bibtex abstract pdf
@ARTICLE{7604118, author={W. Krichene and M. Suarez Castillo and A. Bayen}, journal={IEEE Transactions on Control of Network Systems}, title={On Social Optimal Routing Under Selfish Learning}, year={2016}, volume={PP}, number={99}, pages={1-1}, }We consider a repeated routing game over a finite horizon with partial control under selfish response, in which a central authority can control a fraction of the flow and seeks to improve a network-wide objective, while the remaining flow applies an online learning algorithm. This finite horizon control problem is inspired from the one-shot Stackelberg routing game. Our setting is different in that we do not assume that the selfish players play a Nash equilibrium; instead, we assume that they apply an online learning algorithm. This results in an optimal control problem under learning dynamics. We propose different methods for approximately solving this problem: A greedy algorithm and a mirror descent algorithm based on the adjoint method. In particular, we derive the adjoint system equations of the Hedge dynamics and show that they can be solved efficiently. We compare the performance of these methods (in terms of achieved cost and computational complexity) on parallel networks, and on a model of the Los Angeles highway network.
-
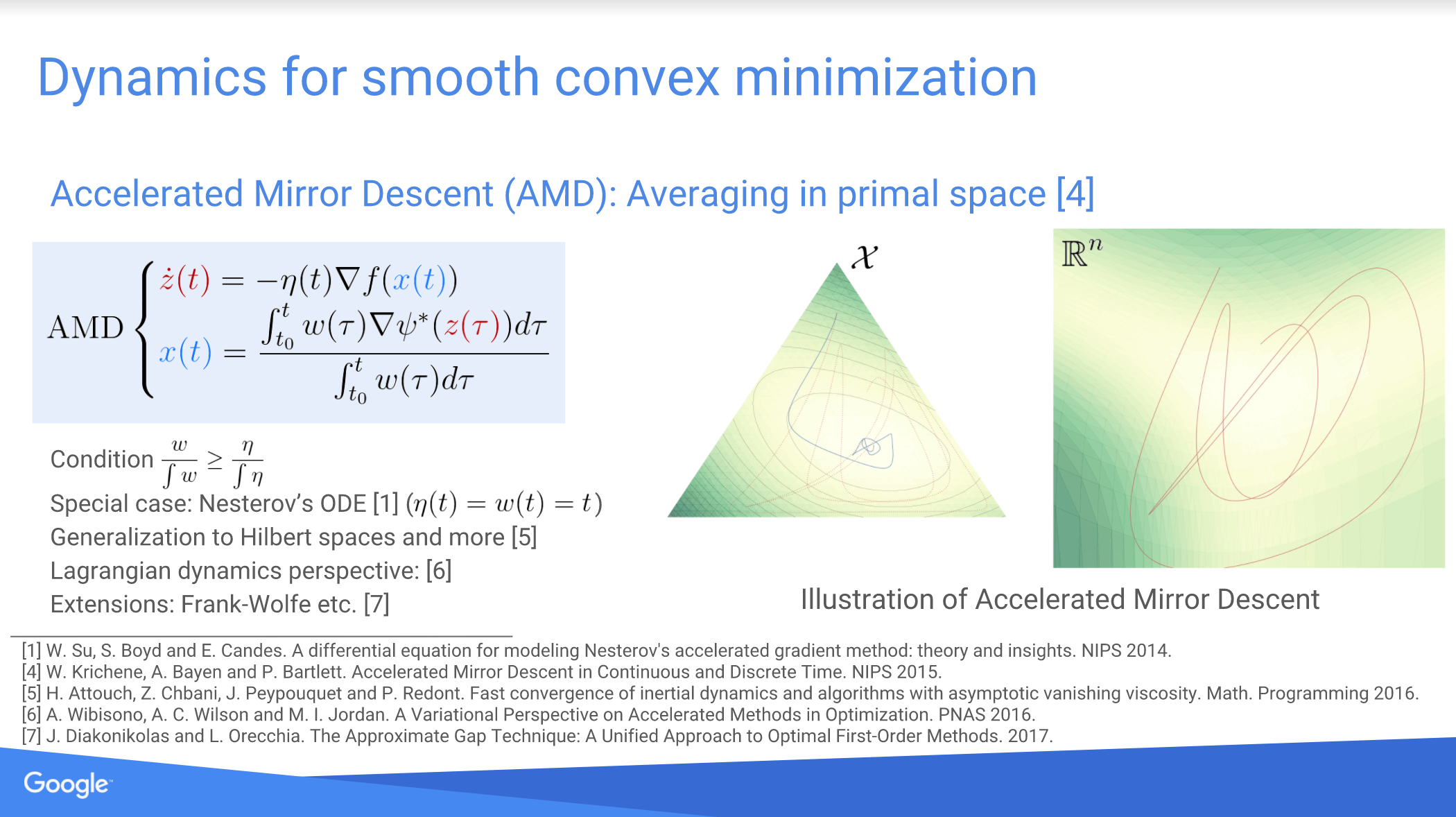
W. Krichene, A. Bayen, P. Bartlett. Accelerated Mirror Descent in Continuous and Discrete Time.
NeurIPS 2015 (spotlight).
bibtex abstract pdf supplement code
@incollection{NIPS2015_5843, title = {Accelerated Mirror Descent in Continuous and Discrete Time}, author = {Krichene, Walid and Bayen, Alexandre and Bartlett, Peter L}, booktitle = {Advances in Neural Information Processing Systems 28}, editor = {C. Cortes and N. D. Lawrence and D. D. Lee and M. Sugiyama and R. Garnett}, pages = {2845--2853}, year = {2015}, publisher = {Curran Associates, Inc.}, }We study accelerated mirror descent dynamics in continuous and discrete time. Combining the original continuous-time motivation of mirror descent with a recent ODE interpretation of Nesterov's accelerated method, we propose a family of continuous-time descent dynamics for convex functions with Lipschitz gradients, such that the solution trajectories are guaranteed to converge to the optimum at a O(1/t^2) rate. We then show that a large family of first-order accelerated methods can be obtained as a discretization of the ODE, and these methods converge at a O(1/k^2) rate. This connection between accelerated mirror descent and the ODE provides an intuitive approach to the design and analysis of accelerated first-order algorithms.
-
W. Krichene, S. Krichene, and A. Bayen. Efficient Bregman Projections onto the Simplex. IEEE Conference on Decision and Control (CDC) 2015.
bibtex abstract pdf code
@INPROCEEDINGS{7402714, author={W. Krichene and S. Krichene and A. Bayen}, booktitle={2015 54th IEEE Conference on Decision and Control (CDC)}, title={Efficient Bregman projections onto the simplex}, year={2015}, pages={3291-3298}, doi={10.1109/CDC.2015.7402714}, month={Dec}, }We consider the problem of projecting a vector onto the simplex Δ = {x ∈ ℝ+d : Σi=1d xi = 1}, using a Bregman projection. This is a common problem in first-order methods for convex optimization and online-learning algorithms, such as mirror descent. We derive the KKT conditions of the projection problem, and show that for Bregman divergences induced by ω-potentials, one can efficiently compute the solution using a bisection method. More precisely, an ω-approximate projection can be obtained in O(d log 1/ω). We also consider a class of exponential potentials for which the exact solution can be computed efficiently, and give a O(d log d) deterministic algorithm and O(d) randomized algorithm to compute the projection. In particular, we show that one can generalize the KL divergence to a Bregman divergence which is bounded on the simplex (unlike the KL divergence), strongly convex with respect to the ℓ1 norm, and for which one can still solve the projection in expected linear time.
-
W. Krichene, B. Drighes, and A. Bayen. Online Learning of Nash Equilibria in Congestion Games. SIAM Journal on Control and Optimization, 2015.
bibtex abstract arxiv
@article{krichene2015congestion, author = {Walid Krichene and Benjamin DrighÚs and Alexandre M. Bayen}, title = {Online Learning of Nash Equilibria in Congestion Games}, journal = {SIAM Journal on Control and Optimization}, volume = {53}, number = {2}, pages = {1056-1081}, year = {2015}, doi = {10.1137/140980685}, }We study the repeated, nonatomic congestion game, in which multiple populations of players share resources and make, at each iteration, a decentralized decision on which resources to utilize. We investigate the following question: given a model of how individual players update their strategies, does the resulting dynamics of strategy profiles converge to the set of Nash equilibria of the one-shot game? We consider in particular a model in which players update their strategies using algorithms with sublinear discounted regret. We show that the resulting sequence of strategy profiles converges to the set of Nash equilibria in the sense of Cesàro means. However, convergence of the actual sequence is not guaranteed in general. We show that it can be guaranteed for a class of algorithms with a sublinear discounted regret and which satisfy an additional condition. We call such algorithms AREP (approximate replicator) algorithms, as they can be interpreted as a discrete-time approximation of the replicator equation, which models the continuous-time evolution of population strategies, and which is known to converge for the class of congestion games.
-
S. Krichene, W. Krichene, R. Dong, and A. Bayen. Convergence of Heterogeneous Distributed Learning in Stochastic Routing Games. Allerton Conference on Communication, Control, and Computing, 2015.
bibtex abstract pdf
@INPROCEEDINGS{krichene2015heterogeneous, author={S. Krichene and W. Krichene and R. Dong and A. Bayen}, booktitle={2015 53rd Annual Allerton Conference on Communication, Control, and Computing (Allerton)}, title={Convergence of heterogeneous distributed learning in stochastic routing games}, year={2015}, volume={}, number={}, pages={480-487}, month={Sept}, }We study convergence properties of distributed learning dynamics in repeated stochastic routing games. The game is stochastic in that each player observes a stochastic vector, the conditional expectation of which is equal to the true loss (almost surely). In particular, we propose a model in which every player m follows a stochastic mirror descent dynamics with Bregman divergence Dψm and learning rates ηtm = θmt-αm. We prove that if all players use the same sequence of learning rates, then their joint strategy converges almost surely to the equilibrium set. If the learning dynamics are heterogeneous, that is, different players use different learning rates, then the joint strategy converges to equilibrium in expectation, and we give upper bounds on the convergence rate. This result holds for general routing games (no smoothness or strong convexity assumptions are required). These results provide a distributed learning model that is robust to measurement noise and other stochastic perturbations, and allows flexibility in the choice of learning algorithm of each player. The results also provide estimates of convergence rates, which are confirmed in simulation.
-
R. Dong, W. Krichene, A. Bayen, and S. Sastry. Differential Privacy of Populations in the Routing Game. IEEE Conference on Decision and Control (CDC) 2015.
bibtex abstract pdf arxiv
@INPROCEEDINGS{dong2015differential, author={R. Dong and W. Krichene and A. M. Bayen and S. S. Sastry}, booktitle={2015 54th IEEE Conference on Decision and Control (CDC)}, title={Differential privacy of populations in routing games}, year={2015}, volume={}, number={}, pages={2798-2803}, ISSN={}, month={Dec}, }As our ground transportation infrastructure modernizes, the large amount of data being measured, transmitted, and stored motivates an analysis of the privacy aspect of these emerging cyber-physical technologies. In this paper, we consider privacy in the routing game, where the origins and destinations of drivers are considered private. This is motivated by the fact that this spatiotemporal information can easily be used as the basis for inferences for a person's activities. More specifically, we consider the differential privacy of the mapping from the amount of flow for each origin-destination pair to the traffic flow measurements on each link of a traffic network. We use a stochastic online learning framework for the population dynamics, which is known to converge to the Nash equilibrium of the routing game. We analyze the sensitivity of this process and provide theoretical guarantees on the convergence rates as well as differential privacy values for these models. We confirm these with simulations on a small example.
-
W. Krichene, M. Balandat, C. Tomlin, and A. Bayen. The Hedge Algorithm on a Continuum. ICML 2015.
bibtex abstract pdf supplement talk
@InProceedings{pmlr-v37-krichene15, title = {The Hedge Algorithm on a Continuum}, author = {Walid Krichene and Maximilian Balandat and Claire Tomlin and Alexandre Bayen}, booktitle = {Proceedings of the 32nd International Conference on Machine Learning}, pages = {824--832}, year = {2015}, editor = {Francis Bach and David Blei}, volume = {37}, series = {Proceedings of Machine Learning Research}, address = {Lille, France}, month = {07--09 Jul}, publisher = {PMLR}, }We consider an online optimization problem on a subset S of R^n (not necessarily convex), in which a decision maker chooses, at each iteration t, a probability distribution x^(t) over S, and seeks to minimize a cumulative expected loss, where each loss is a Lipschitz function revealed at the end of iteration t. Building on previous work, we propose a generalized Hedge algorithm and show a O(\sqrtt \log t) bound on the regret when the losses are uniformly Lipschitz and S is uniformly fat (a weaker condition than convexity). Finally, we propose a generalization to the dual averaging method on the set of Lebesgue-continuous distributions over S.
-
W. Krichene, B. Drighes, and A. Bayen. On the Convergence of No-Regret Learning in Selfish Routing. ICML 2014.
bibtex abstract pdf supplement talk
@InProceedings{pmlr-v32-krichene14, title = {On the convergence of no-regret learning in selfish routing}, author = {Walid Krichene and Benjamin Drighès and Alexandre Bayen}, booktitle = {Proceedings of the 31st International Conference on Machine Learning}, pages = {163--171}, year = {2014}, editor = {Eric P. Xing and Tony Jebara}, volume = {32}, number = {2}, series = {Proceedings of Machine Learning Research}, address = {Bejing, China}, month = {22--24 Jun}, publisher = {PMLR}, }We study the repeated, non-atomic routing game, in which selfish players make a sequence of routing decisions. We consider a model in which players use regret-minimizing algorithms as the learning mechanism, and study the resulting dynamics. We are concerned in particular with the convergence to the set of Nash equilibria of the routing game. No-regret learning algorithms are known to guarantee convergence of a subsequence of population strategies. We are concerned with convergence of the actual sequence. We show that convergence holds for a large class of online learning algorithms, inspired from the continuous-time replicator dynamics. In particular, the discounted Hedge algorithm is proved to belong to this class, which guarantees its convergence.
-
B. Drighes, W. Krichene, and A. Bayen. Stability of Nash Equilibria in the Congestion Game under Replicator Dynamics. IEEE Conference on Decision and Control (CDC) 2014.
bibtex abstract pdf
@INPROCEEDINGS{7039679, author={B. Drighès and W. Krichene and A. Bayen}, booktitle={53rd IEEE Conference on Decision and Control}, title={Stability of Nash equilibria in the congestion game under Replicator dynamics}, year={2014}, volume={}, number={}, pages={1923-1929}, doi={10.1109/CDC.2014.7039679}, ISSN={0191-2216}, month={Dec}, }We consider the single commodity non-atomic congestion game, in which the player population is assumed to obey the replicator dynamics. We study the resulting rest points, and relate them to the Nash equilibria of the one-shot congestion game. The rest points of the replicator dynamics, also called evolutionary stable points, are known to coincide with a superset of Nash equilibria, called restricted equilibria. By studying the spectrum of the linearized system around rest points, we show that Nash equilibria are locally asymptotically stable stationary points. We also show that under the additional assumption of strictly increasing congestion functions, Nash equilibria are exactly the set of exponentially stable points. We illustrate these results on numerical examples.
-
J. Reilly, S. Samaranayake, M. Delle Monache, W. Krichene, P. Goatin, and A. Bayen. Adjoint-based optimization on a network of discretized scalar conservation law PDEs with applications to coordinated ramp metering. Journal of Optimization Theory and Applications (JOTA), 2015.
bibtex abstract pdf
@Article{Reilly2015, author="Reilly, Jack and Samaranayake, Samitha and Delle Monache, Maria Laura and Krichene, Walid and Goatin, Paola and Bayen, Alexandre M.", title="Adjoint-Based Optimization on a Network of Discretized Scalar Conservation Laws with Applications to Coordinated Ramp Metering", journal="Journal of Optimization Theory and Applications", year="2015", month="Nov", day="01", volume="167", number="2", pages="733--760", issn="1573-2878", doi="10.1007/s10957-015-0749-1", }The adjoint method provides a computationally efficient means of calculating the gradient for applications in constrained optimization. In this article, we consider a network of scalar conservation laws with general topology, whose behavior is modified by a set of control parameters in order to minimize a given objective function. After discretizing the corresponding partial differential equation models via the Godunov scheme, we detail the computation of the gradient of the discretized system with respect to the control parameters and show that the complexity of its computation scales linearly with the number of discrete state variables for networks of small vertex degree. The method is applied to the problem of coordinated ramp metering on freeway networks. Numerical simulations on the I15 freeway in California demonstrate an improvement in performance and running time compared with existing methods. In the context of model predictive control, the algorithm is shown to be robust to noise in the initial data and boundary conditions.
-
W. Krichene, J. Reilly, S. Amin, A. Bayen. Stackelberg Routing on Parallel Networks with Horizontal Queues. IEEE Transactions on Automatic Control (TAC), 2014.
bibtex abstract pdf
@ARTICLE{6744679, author={W. Krichene and J. D. Reilly and S. Amin and A. M. Bayen}, journal={IEEE Transactions on Automatic Control}, title={Stackelberg Routing on Parallel Networks With Horizontal Queues}, year={2014}, volume={59}, number={3}, pages={714-727}, doi={10.1109/TAC.2013.2289709}, ISSN={0018-9286}, month={March}, }This paper presents a game theoretic framework for studying Stackelberg routing games on parallel networks with horizontal queues, such as transportation networks. First, we introduce a new class of latency functions that models congestion due to the formation of physical queues. For this new class, some results from the classical congestion games literature (in which latency is assumed to be a non-decreasing function of the flow) do not hold. In particular, we find that there may exist multiple Nash equilibria that have different total costs. We provide a simple polynomial-time algorithm for computing the best Nash equilibrium, i.e., the one which achieves minimal total cost. Then we study the Stackelberg routing game: assuming a central authority has control over a fraction of the flow on the network (compliant flow), and that the remaining flow (non-compliant) responds selfishly, what is the best way to route the compliant flow in order to minimize the total cost? We propose a simple Stackelberg strategy, the Non-Compliant First (NCF) strategy, that can be computed in polynomial time. We show that it is optimal for this new class of latency on parallel networks. This work is applied to modeling and simulating congestion relief on transportation networks, in which a coordinator (traffic management agency) can choose to route a fraction of compliant drivers, while the rest of the drivers choose their routes selfishly.
-
M. Delle Monache, J. Reilly, S. Samaranayake, W. Krichene, P. Goatin, and A. Bayen. A PDE-ODE Model for a Junction with Ramp Buffer. SIAM Journal on Applied Mathematics, 2014.
bibtex abstract pdf
@article{doi:10.1137/130908993, author = {M. L. Delle Monache and J. Reilly and S. Samaranayake and W. Krichene and P. Goatin and A. M. Bayen}, title = {A PDE-ODE Model for a Junction with Ramp Buffer}, journal = {SIAM Journal on Applied Mathematics}, volume = {74}, number = {1}, pages = {22-39}, year = {2014}, doi = {10.1137/130908993}, }We consider the Lighthill--Whitham--Richards traffic flow model on a junction composed by one mainline, an onramp, and an offramp, which are connected by a node. The onramp dynamics is modeled using an ordinary differential equation describing the evolution of the queue length. The definition of the solution of the Riemann problem at the junction is based on an optimization problem and the use of a right-of-way parameter. The numerical approximation is carried out using a Godunov scheme, modified to take into account the effects of the onramp buffer. We present the result of some simulations and numerically check the convergence of the method.